
Related Articles

There are a few key statistics that I’d like to share before actually getting into the post. There are about 2 Billion websites currently on the internet. And we are generating close to 2.5 quintillion bytes of data daily. (I can’t even count the number of zeros in there) From that like to that tweet to that Instagram post, this blog post, videos and all other forms of content contribute to this huge number.
When it comes to creating content, there are only quite a few of them who are genuinely creating content while others are just copying or scraping them. Content Scraping to be specific. Few folks will recycle and repurpose old content while others indulge in content scraping. Have you been a victim of content scraping ? Has you blog’s content copied on another website without your approval ? I’ll be sharing some tips on how to prevent content scraping.
What is content scraping ?
First things first, what exactly is content scraping ? Content scraping or web scraping as it is known is an activity when a bot(robot) downloads entire content from websites regardless of owner’s wishes. This is essentially a theft of unique/original content from websites which are published elsewhere to drive traffic. I’ve heard many of my blogging friends talk about it on Twitter that there blog posts are being copied and they aren’t able to do anything.
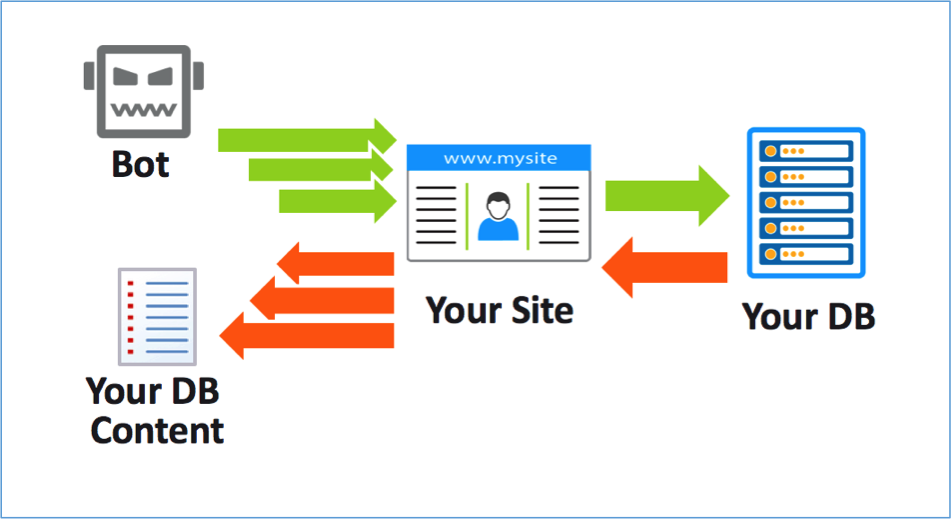
Over the last few days, I have been a victim of the content scraping. Not much can be done about the content that is already copied apart from requesting the owner or raising a complaint with the web hosting. However, I decided to spend some time to prevent content scraping in future. So this is going to be an informational post for all the content creators, specially bloggers.
How to identify content scraping ?
So how does one come to know whether their content is being copied or not ? There are numerous ways to know about it. However, none of these methods will inform you immediately. There is no particular order to identify the act of content scraping, however following are the ways you can identify if your content is being copied.
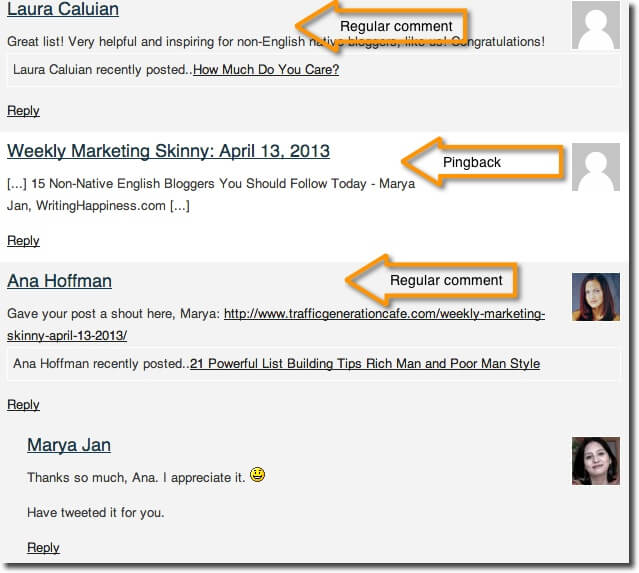
One of the easiest ways to identify content scraping is through your blogging control panel. This is applicable only to WordPress users. WordPress has a unique feature of Trackbacks and Pingbacks with which it notifies a site whether any of it’s post was shared anywhere. So when someone scrapes your content, you will see a comment (mostly under spam comments) with the url of the blog post along with the site it has been posted at along with the IP address.
Another way (tough) is to refer to the access logs of your website/blog. Now most of you I assume are on a shared hosting plan and never look at access logs. The access logs of your web server provide you with exact details of who accessed what from where and at what time. If you understand Apache/NGINX server logs, then you can easily spot a missing referrer or a user agent or the type of requests as well.

Lastly, some of your friends are browsing the internet and they find the exact same blog post/image being posted on some other website and they tell this to you.
These are a few ways with which you can identify content scraping. There might be other ways too, but these are a few common ones which any blogger can user.
Victim of Content Scraping ? What Next ?
Once you have identified that your content is being copied blatantly, what should you do next ? Though many times the websites doing this activity do mention your blog as the original source. And even if you read about this topic, many people advise to ignore it since not much can be done. Nonetheless, what should you do when you are a victim of content scraping ?
The first and foremost way is to reach out to the owner of the website. This can be done via the contact page of the website that is copying your content. However, there are a lot of cases when such site don’t have a contact page.
If that happens, let’s go to the WHOIS details of the domain name. WHOIS details contain information about the owner, domain and hosting details. IFF the owner hasn’t enabled privacy protection (which many people do today) then you should be able to see the email id/ contact details of the site owner. Contact them and ask to pull down the content.

I tried doing that, I got the mail id from the WHOIS details, reached out to the person. I wasn’t expecting a reply, but I got one. “Sure, I’ll do it” Now most of the content scraping is done by bots and not humans. So I couldn’t actually trust this guy on this. And in fact the next morning I saw 3 of my other blog posts being put up on his blog.
Another way to prevent content scraping is to raise a DMCA complaint with the hosting provider. You can find the hosting provider of the domain name from WHOIS details. (If they are using a different DNS provider like Cloudflare, it’s tough to find the actual domain host) Once you find the hosting provider, search for their DMCA email id and write a mail mentioning the theft.
These are the only two things that you can do if you are a victim of content scraping. However, in my case, this has been going on for a few days now and I had to stop this. So how do you prevent yourself from content scraping ?

Prevent Content Scraping on your blog
If you are here, it means you already know who is scraping your content, and where they are putting it up. To prevent content scraping in future, below are a few things you can do. Do note that there is a good degree of technical expertise needed to ensure this is done correctly. Any error will lead your website being down.
Before we actually start looking into this, we need to have analyzed the server logs. Because this is where we can find the culprit. The comments section does show an IP address, but since these are bots, the IP address will keep changing. We need to look at just one thing here, the HTTP-USER-AGENT.

User Agent is a variable that is sent with the request when loading a website. It basically tells the server who is accessing the website. This generally contains the browser and the device details used to access the website. However, when content scraping is done, the UA is either blank or it has a name. If your website is running on an Apache server, you can access the access logs and you will find something like this:
This image may vary for each of you depending on the log format being used. Based on that, I can find the user agent, once I have that I need to find a way to block request from this user agent.
Some of you might think that putting a “Disable Right Click” plugin would work. But it will not. Since these are bots accessing the content and not humans, they never reach your website from a traditional browser.
Based on my understanding of the subject there are two ways to prevent content scraping. Do note that even if you are on shared hosting, you will be able to make these changes as most of the shared hosting services use virtual hosts. If you are using a VPS or any other service, this will work too.
- Via Server configuration
- Via Cloudflare
Via Server configuration
This is one of the effective ways to prevent content scraping by bots. Now that you know who is copying your content (User Agent) Simply block the request in your server configuration. If your site is running on an Apache server, you can block this bot via the .htaccess file that is present at the www root . You can use a configuration like below to block the request.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Textbot [NC]
RewriteRule .* - [F,L]Replace Textbot with the user agent name you got from the logs. Put this code inside an Rewrite IFModule tag and restart your Apache server (mandatory for the changes to take effect) If everything goes fine, the next time a request comes in from the user agent, you shall see status code 403 (Forbidden) in your access logs. If you are using NGINX server, then you will need to make changes in the nginx.conf file and add the following code
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}In this way you are blocking the bot to access your server and copy your data. Though this works, it still allows the request to reach to your server. Another way to block this request even before the request reaches the server is via Cloudflare.
Via Cloudflare
Cloudflare is a widely used DNS service that is quite effective. It comes with a state of the art DDoS protect along with a whole lot of services including cache control and SSL. It’s free service is used by a lot of people around the globe. Though limited features, it does good for people like you and me.
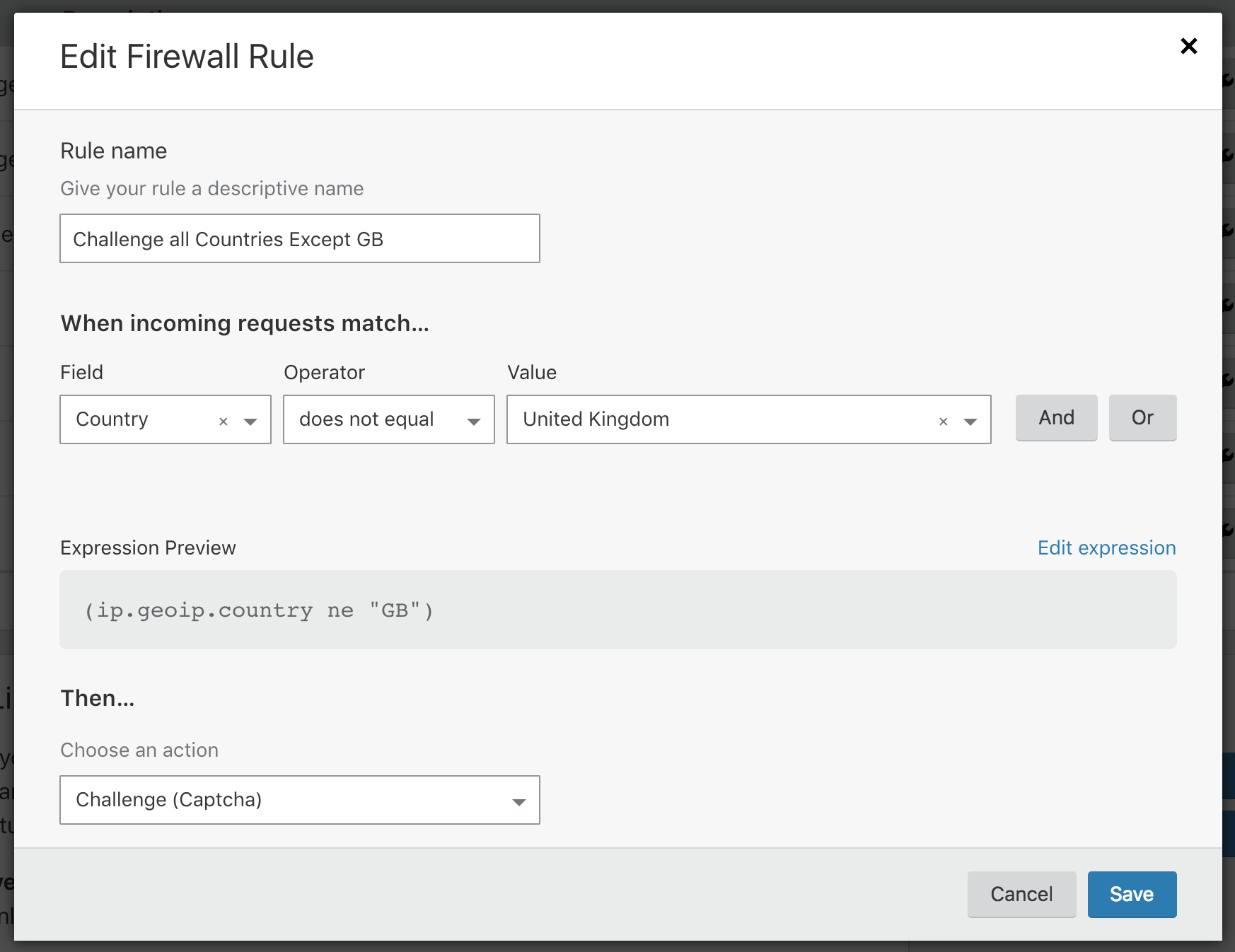
You can log in to your Cloudflare control panel and navigate to Firewall. In it’s free tier, Cloudflare provides 5 free firewall rules. So please use them judiciously. All you need to do is to add a new firewall rule.
On the page, provide a name for your rule. From the drop down, choose a field. This is the field which will be used to identify the request. We need to choose HTTP_User_Agent in the field. Choose “equal to” under operator and in the value field paste the User Agent that we got from the access logs. Save the logs and you’re good to go.
You can test this by sending a GET request from Postman or similar tool and add the HTTP-USER-AGENT parameter in the request header. In response you should get Error 403 with the Cloudflare text saying, your request is blocked. The advantage of this method is that it blocks the request even before it reaches your server. The disadvantage (maybe) is that you don’t see it in the Apache logs, you need to check Clouldflare logs for this.
Prevent Content Scraping
Phew ! That was quite a bit of a blog post. I don’t know how many of you will understand this as this is quite technical but these are the only ways you can do something to prevent content scraping. I’ve been a victim of content scraping and I’m using a mix of these to prevent it in future.
Over the last few weeks, I haven’t seen any content being scraped so I can assume things are fine. Have you been a victim on content scraping ever ? What did you do back then ? Will you use any of these techniques to prevent it in future ? Share your thoughts in the comments below or tweet to me at @Atulmaharaj or DM me on Instagram.


Very informative and most helpful post, Atul! A need of the hour post. You have explained the steps to prevent content scraping in a simple yet powerful way! Keep writing!
Thanks a lot Vasanthaji, glad you found this insightful 🙂
A very detailed and well researched article Atul.Hope your problem is solved now
Yes, thanks for dropping by Amritaji:)
Extremely informative. I have been a victim of content scraping multiple teams and the reasoning people come up is rather amusing.
Thanks Rituji, many people don’t realize that their content is being scrapped.
Very informative. Thanks for sharing sir.
Glad you found this helpful. Thanks for dropping by.